What is Unicode and why was it introduced
What is Unicode and why was it introduced?
✍: Guest
In order to understand the concept of Unicode we need to move little back and understand
ANSI code. ASCII (ask key) stands for American Standard Code for Information
Interchange. In ASCII format every character is represented by one byte (i.e. 8 bits). So in
short we can have 256 characters (2^8). Before UNICODE came in to picture programmers
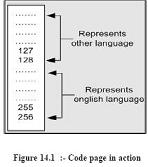
used code page to represent characters in different languages. Code page is a different
interpretation of ASCII set. Code pages keep 128 characters for English and the rest 128
characters are tailored for a specific language.
Below is a pictorial representation of the same.
There are following disadvantages of the CODE page approach:
Some languages like Chinese have more than 5000 characters which is difficult to
represent only 128 character set.
Only two languages can be supported at one time. As said in the previous note you
can use 128 for English and the rest 128 for the other language.
The end client should have the code page.
Code Representation change according to Operating system and Language used.
That means a character can be represented in different numbers depending on
operating system.
For all the above problems UNICODE was introduced. UNICODE represents characters
with 2 bytes. So if its two bytes that means 18 bits. You can now have 2^16 characters i.e.
65536 characters. That's a huge number you can include any language in the world. Further
if you use surrogates you can have additional 1 million characters...Hmm that can include
type of language including historian characters.
ASCII representation varied according to operating system and language. But in
UNICODE it assigns a unique letter for every character irrespective of Language or
operating system which makes programmers life much easier while developing international
compatible applications.
2007-11-01, 5515👍, 0💬
Related Topics: